简介:Java 日常比较零碎的知识点记录:Java 线程线程池,线程通信,Java 泛型,Stream,Lambda表达式,Java 加密算法,Java mail,Java 队列
线程
两个特性
在多个线程共享某个对象X时,X首先存在于主线程的堆内存中,不同的线程对X的操作实际上是,分3步完成,首先拷贝副本到线程栈中,然后执行某些操作,最后将X回刷回主线程的堆内存。
可见性 :
多线程中,某些线程对X进行修改,其他线程也能看到被修改的X 此为可见性有序性 :
对X的操作,如果要求必须等到前一个线程完整之后,后一次线程才操作 此为有序性
Main 方法执行中,如果另起线程中,线程挂起,主线程是不会关闭的
JUnit 执行测试时,如果另起线程中,线程挂起,主线程任然会关闭
Java 1.5之前对线程同步的方式
synchronized
- 修饰一个代码块,其同步的作用域是{}之间的代码,锁是()里面的东西,作用的对象是调用该代码块的类(及一个时间只有一个对象可以调用这个代码块)
- 修饰一个方法,其同步的是作用域是整个方法里面的代码,锁 是当前方法所属的对象,作用的对象是调用当前方法的对象(及一个时间只有一个对象可以调用该方法)
- 修饰一个静态方法,其同步的作用域是整个方法里面的代码,锁是当前方法所属类A,而类所有的实例都是共用一个类的,故对所有实例都有效(及一个时间只有一个对象可以调用该方法,更加严格的,两个类A的实例给其他对象加锁用,但这两个类A都是用的同一把锁)
- 修改一个类,其所有方法同步,锁是当前类A,同第3点
volatile
volatile 具有synchronized的可见性,不具有synchronized的有序性(原子性),
- 其性能优于synchronized
- 严格遵循 volatile 的使用条件 —— 即变量真正独立于其他变量和自己以前的值
- volatile只能保证对单次读/写的原子性
对volatile 修饰的变量的与普通的变量修改的区别有两点
- 修改volatile变量的会强制将修改后的值刷新到主内存中
- 修改volatile变量的会造成其他线程对该变量应用的失效
volatile关键字只能保证get操作是读取的是最新的值,而set操作会写到内存中,会强制重新从系统内存里把数据读到处理器缓存里,并不具有原子性
适用场景
- 一个地方写,很多地方读取,这个时候使用volatile会让每个地方获取的值都是最新的
volatile 和 synchronized 实现 “开销较低的读-写锁”
public class CheesyCounter { private volatile int value; public int getValue() { return value; } public synchronized int increment() { return value++; } }
ThreadPoolExecutor线程池
解决目的
线程的创建,消费,对内存的开销很大,创建线程也会带来额外的性能支出(如创建时间),ThreadPoolExecutor(从1.5版本开始)
构造方法
有4个,但都是由下面这个变种
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
// corePoolSize :核心池大小数,在创建线程池对象的时候,核心池的大小其实是0的,然后在往线程池里面添加任务的时候,初始化一个线程
// maximumPoolSize:池最大数,表示当前当前线程池允许的最大线程数
// keepAliveTime:空闲线程允许存活时间,当线程空闲时,这个线程等待多长时间进行释放回收,
// TimeUnit: 时间类型,keepAliveTime的时间类型参数(7种)
// workQueue:阻塞队列,用来存储等待执行的任务,有多种如 `ArrayBlockingQueue` `LinkedBlockingQueue` `SynchronousQueue`
ArrayBlockingQueue:基于数组实现,初始时,需要指定大小,先进先出
LinkedBlockingQueue:基于链表的实现,初始时,可不指定大小,默认为Int的max,先进先出
SynchronousQueue:该队列不会保存任务,直接提交执行
// threadFactory :线程工厂
// handler:表示拒绝服务的策略(有4种)
ThreadPoolExecutor.AbortPolicy:丢弃任务并抛出RejectedExecutionException异常。
ThreadPoolExecutor.DiscardPolicy:也是丢弃任务,但是不抛出异常。
ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列最前面的任务,然后重新尝试执行任务(重复此过程)
ThreadPoolExecutor.CallerRunsPolicy:由调用线程处理该任务
Executors 工具类
1 | ExecutorService service = Executors.newFixedThreadPool(4); |
数据结构
- 从逻辑上说:集合,线形,树形,图形
- 从物理上说:顺序,链式,索引,散列
常见的数据结构
- 线性表(链表)
- 队列 (先进先出)
- 栈(后进先出)
- 树
- 图
二叉搜索树
- 二叉搜索树的特点是,小的值在左边,大的值在右边,即
- 如实例:
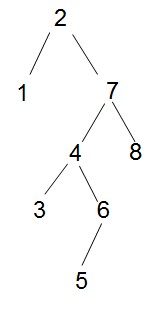
可以非常方便的获取最大值,最小值,某元素的前驱,某元素的后驱
最大值:树的最右节点。
最小值:树的最左节点。
某元素前驱:左子树的最右。
某元素的后继:右子树的最左。
由上可知,二叉搜索树的dictionary operation(包括search、insertion、deletion)的时间复杂度均与O(h)相关,h为树的高度(log n),如果按照上述的insertion方法构建树,那么构建出来的树的形状各异,特别是当输入序列有序时,更会退化到链表的程度。所以,如果能用某种方法,将树的高度降低到最小,那么其dictionary operation的时间开销均可以降低,不过相对而言构建树的开销将增大。为了降低二叉搜索树的高度而提出了平衡二叉树(Balanced Binary Tree)的概念。它要求左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。这样就可以将搜索树的高度尽量减小。常用算法有红黑树、AVL、Treap、伸展树等。
扩展(对数 )
- log表示对数。
- 如果a^n = b(a>0,且a≠1),那么数n叫做以a为底b的对数,记做n=log(a)b,【a是下标】
- 其中,a叫做“底数”,b叫做“真数”。
- 相应地,函数y=logaX叫做对数函数。对数函数的定义域是(0,+∞)。零和负数没有对数。
- 底数a为常数,其取值范围是(0,1)∪(1,+∞)。
- 当a=10时,写作:y=lgx【常用对数】。
- 当a=e【自然对数的底数】时,写作y=lnx
- 例:2^3 =8
- 那么 log(2) 8 = 3
插件
Eclipse Scala 插件
安装文档及说明地址: http://scala-ide.org/download/current.html
Maven maven-assembly-plugin 插件
在 pom.xml < build> 里面 添加插件
打单独包的插件
1 | <plugin> |
assembly.xml
1 | <assembly xmlns="http://maven.apache.org/ASSEMBLY/2.0.0" |
Java Puzzlers
- URL的equals比对方式,在有网时,会根据解析地址来判断,地址相同则相同,在没网时,会根据字符串来判断,但是域名不区分大小写
- j++ 与 ++j 这种运算存在一个临时中间变量
- static 方法是类的,不会被继承
- for 循环只有一行时,可以省下{} ,但是不能是赋值语句
- Integer 与int相比,值等就等,Integer对象之间比较,在byte范围内,必然相等
- BigInteger.add()方法,返回的是加的结果,原值是不会改变的
- BigInteger 与BigDecimal 具有相同方法,2个都是处理大数据精确计算的,一个是整数相关,一个是浮点数相关
- Integer 静态方法,可以方便的转换2/8/16进制
- 基本上所有容器类的构造方法都有参数为容器的
- << 与 >> 为位运算,表示将二进制左右移动,很方便的实现开方
- String.format() 工具类,可快速格式化
- Char 在英文编码范围是有缓存的,故包装类之间比较这个范围,是相等的
- Math.abs() Integer.min() 的时候,自身相等
- java的重载方法,在调用的时候,会选取最适中的
- Number是所有数字类的父类
- Class.forName() 将类加入编译环境 ,c.newInstance() 会调用无参构造方法
- Timer 与TimerTask 两个是java处理定时器相关的两个类
Java Generics 泛型
- 必须先声明
可在类上 或者方法上声明 - 是否拥有泛型方法 跟是否是泛型类 无关
- 泛型在编译阶段中,会将泛型进行擦除,也就是说成功编译后的泛型,是不包含任何泛型信息的
- 多重泛型 类放第一位,接口从第二位开始,用& 连接
1 | <T extends SomeClass & interface1 & interface2 & interface3> |
Java Lambda 表达式
替代只有一个抽象方法的接口在代码内中匿名直接使用 (自1.8之后引入,是Stream的使用基础)
格式
参数列表 -> 函数体
- 参数列表有() 括起来,如果只有一个,可省略括号
- 函数体 可以是一个表达式,也可以是一个语句块{}
返回
如果函数体是一个表达式,会将执行结果返回给匿名调用者
如果是语句块,会将return 返回给调用者
内部接口单一方法替代
需要接口中只有单一抽象方法
() -> 代替内部匿名接口
函数体引用值
在lambda中,引入外部变量,可不定义成final,但是其本质还是final的
闭包,运行我们创建函数指针,并把他们作为参数传递
1 | public interface Geek { |
集合迭代
1 | public static void main(String[] args) { |
函数接口
是Java 8 对一类特殊类型的接口的称呼,这类接口只定义一个唯一抽象方法,用作lambda表达式
具体的类的方法,必须跟函数接口声明一致,方法必须为static
@FunctionalInterface 可以在函数接口上声明,便于编译器优化,如果不是函数接口,那么添加注解会报错
1 | Magic5 m6 = MyMagic::show; |
Java Stream 语法
Stream 是Java 8 推出
Stream 是用函数式编程的方式来处理集合类上的负责操作(循环,查找,过滤等)
其一系列的操作都是在操作Stream,直到feach时才会操作结果,这种迭代方式称为内部迭代。(在一次聚合操作中,可以有多个Intermediate,但是有且只有一个Terminal)
使用流程
- 创建Stream:通过stream()方法等,取得集合对象的数据集。
- Intermediate:通过一系列中间(Intermediate)方法,对数据集进行过滤、检索等数据集的再次处理。如上例中,使用filter()方法来对数据集进行过滤。
- Terminal通过最终(terminal)方法完成对数据集中元素的处理。如上例中,使用forEach()完成对过滤后元素的打印。
Stream的操作分类
- Intermediate:map (mapToInt, flatMap 等)、 filter、 distinct、 sorted、 peek、 skip、 parallel、 sequential、 unordered
- Terminal:forEach、 forEachOrdered、 toArray、 reduce、 collect、 min、 max、 count、iterator
- Short-circuiting: anyMatch、 allMatch、 noneMatch、 findFirst、 findAny、 limit
1 | long count = allArtists.stream() |
惰性求值和及早求值方法
- 如何判断一个操作是惰性求值还是及早求值,其实很简单,只需要看其返回值即可:如果返回值是Stream,那么就是惰性求值;如果返回值不是Stream或者是void,那么就是及早求值。上面的示例中,只是包含两步:一个惰性求值-filter和一个及早求值-count。
- 前面,已经说过,在一个Stream操作中,可以有多次惰性求值,但有且仅有一次及早求值。
创建方法
- Stream接口提供的静态方法,of,generate,iterate
1 |
|
Collection接口和数组的默认方法
Collection集合类,在接口上已经实现抽象,
数组是使用静态的方法进行实现
1
Arrays.stream(ga).forEach(i -> System.out.println(i.getName()));
其他创建Stream
1
2
3
4Random.ints()
BitSet.stream()
Pattern.splitAsStream(java.lang.CharSequence)
JarFile.stream()
Intermediate
Intermediate主要是用来对Stream做出相应转换及限制流,实际上是将源Stream转换为一个新的Stream,以达到需求效果。
- concat方法将两个Stream连接在一起,合成一个Stream
- distinct方法以达到去除掉原Stream中重复的元素,生成的新Stream中没有没有重复的元素。
- filter方法对原Stream按照指定条件过滤,在新建的Stream中,只包含满足条件的元素,将不满足条件的元素过滤掉。
- map方法将对于Stream中包含的元素使用给定的转换函数进行转换操作,新生成的Stream只包含转换生成的元素。为了提高处理效率,官方已封装好了,三种变形:mapToDouble,mapToInt,mapToLong。其实很好理解,如果想将原Stream中的数据类型,转换为double,int或者是long是可以调用相对应的方法。
- flatMap方法与map方法类似,都是将原Stream中的每一个元素通过转换函数转换,不同的是,该换转函数的对象是一个Stream,也不会再创建一个新的Stream,而是将原Stream的元素取代为转换的Stream。如果转换函数生产的Stream为null,应由空Stream取代。flatMap有三个对于原始类型的变种方法,分别是:flatMapToInt,flatMapToLong和flatMapToDouble。
- peek方法生成一个包含原Stream的所有元素的新Stream,同时会提供一个消费函数(Consumer实例),新Stream每个元素被消费的时候都会执行给定的消费函数,并且消费函数优先执行
- skip方法将过滤掉原Stream中的前N个元素,返回剩下的元素所组成的新Stream。如果原Stream的元素个数大于N,将返回原Stream的后(原Stream长度-N)个元素所组成的新Stream;如果原Stream的元素个数小于或等于N,将返回一个空Stream。
- sorted方法将对原Stream进行排序,返回一个有序列的新Stream。sorterd有两种变体sorted(),sorted(Comparator),前者将默认使用Object.equals(Object)进行排序,而后者接受一个自定义排序规则函数(Comparator),可按照意愿排序。
Terminal
- count方法将返回Stream中元素的个数。
- forEach方法前面已经用了好多次,其用于遍历Stream中的所元素
- forEachOrdered方法与forEach类似,都是遍历Stream中的所有元素,不同的是,如果该Stream预先设定了顺序,会按照预先设定的顺序执行(Stream是无序的),默认为元素插入的顺序。
- max方法根据指定的Comparator,返回一个Optional,该Optional中的value值就是Stream中最大的元素
- min方法根据指定的Comparator,返回一个Optional,该Optional中的value值就是Stream中最小的元素
Short-circuiting
allMatch操作用于判断Stream中的元素是否全部满足指定条件。如果全部满足条件返回true,否则返回false。
anyMatch操作用于判断Stream中的是否有满足指定条件的元素。如果最少有一个满足条件返回true,否则返回false。
findAny操作用于获取含有Stream中的某个元素的Optional,如果Stream为空,则返回一个空的Optional。由于此操作的行动是不确定的,其会自由的选择Stream中的任何元素。在并行操作中,在同一个Stram中多次调用,可能会不同的结果。在串行调用时,Debug了几次,发现每次都是获取的第一个元素,个人感觉在串行调用时,应该默认的是获取第一个元素。
findFirst操作用于获取含有Stream中的第一个元素的Optional,如果Stream为空,则返回一个空的Optional。若Stream并未排序,可能返回含有Stream中任意元素的Optional。
limit方法将截取原Stream,截取后Stream的最大长度不能超过指定值N。如果原Stream的元素个数大于N,将截取原Stream的前N个元素;如果原Stream的元素个数小于或等于N,将截取原Stream中的所有元素。
noneMatch方法将判断Stream中的所有元素是否满足指定的条件,如果所有元素都不满足条件,返回true;否则,返回false.
Java信息安全
BASE64,MD5,SHA,HMAC,RIPEMD算法
- Base64编码格式
- base58编码(比特币使用)
- Md5(摘要算法)
- SHA (安全哈希算法,包含SHA-1,SHA-224,SHA-256,SHA-384,和SHA-512这几种单向散列算法。SHA-1,SHA-224和SHA-256适用于长度不超过2^64二进制位的消息。SHA-384和SHA-512适用于长度不超过2^128二进制位的消息。sha1已不推荐使用)
对称加密算法
- DES (Data Encryption Standard,数据加密标准)
- 3DES (Triple DES,三重数据加密算法(TDEA,Triple Data Encryption Algorithm))
- AES (Advanced Encryption Standard,高级加密标准)
- RC4
对称加密是最快速、最简单的一种加密方式,加密(encryption)与解密(decryption)用的是同样的密钥(secret key),这种方法在密码学中叫做对称加密算法。
非对称加密算法RSA
- RSA算法(Ron Rivest、Adi Shamir、Leonard Adleman,人名组合)
你只要想:既然是加密,那肯定是不希望别人知道我的消息,所以只有我才能解密,所以可得出公钥负责加密,私钥负责解密;同理,既然是签名,那肯定是不希望有人冒充我发消息,只有我才能发布这个签名,所以可得出私钥负责签名,公钥负责验证。
非对称加密为数据的加密与解密提供了一个非常安全的方法,它使用了一对密钥,公钥(public key)和私钥(private key)
JAVA 证书制作
使用java自带的工具keytool.exe生成
生成keyStore文件
keytool -genkey -validity 36000 -alias www.felicity.org -keyalg RSA -keystore d:\felicity.keystore
* -genkey表示生成密钥
* -validity指定证书有效期,这里是36000天
* -alias指定别名,这里是www.felicity.org
* -keyalg指定算法,这里是RSA
* -keystore指定存储位置,这里是d:\felicity.keystore
在这里我使用的密码为 123456
生成自签名证书
keytool -export -keystore d:\felicity.keystore -alias www.felicity.org -file d:\felicity.cer -rfc
* -export指定为导出操作
* -keystore指定keystore文件
* -alias指定导出keystore文件中的别名
* -file指向导出路径
* -rfc以文本格式输出,也就是以BASE64编码输出
这里的密码是 123456
已经生成了.cer 的证书了
文件长度获取
① 如果要从网络中下载文件时,我们知道网络是不稳定的,也就是说网络下载时,read()方法是阻塞的,说明这时我们用inputStream.available()获取不到文件的总大小。
此时就需要通过来获取文件的大小。1
2HttpURLConnection httpconn = (HttpURLConnection)url.openConnection();
httpconn.getContentLength();//获取文件长度② 如果是本地文件的话,用此方法 inputStream.available() 就返回实际文件的大小。
- ③ 这个方法其实是通过文件描述符获取文件的总大小,而并不是事先将磁盘上的文件数据全部读入流中,再获取文件总大小
Java Mail
邮件是在很多不同服务器之间进行数据传递,那么必然需要一个接收,发送传输规则
协议
- SMTP (simple mail transfer protocol) 即 简单邮件传输协议,属于TCP/IP协议族 用于发送邮件, 默认端口25
- POP3 (post office protocol 3) 即邮局协议第3个版本, 用于接收邮件 默认端口 110
- IMAP (internet mail access protocol) 即 交互式邮件存取协议,类式POP3 ,不同点在于开启IMAP协议之后,在邮件客户端上的操作会反馈到邮件服务器上 默认端口143
发送邮件流程
- 邮箱账户连接上邮件服务器,获取session
- 通过session,对外发送邮件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25// 地址
Address sendFrom = new InternetAddress(fromUserName,pref,"UTF-8");
Address sendTo = new InternetAddress(to);
// 连接mail
Properties props = new Properties();
props.put("mail.smtp.auth", "true");
props.put("mail.smtp.host", "smtp.163.com");
Session session = Session.getInstance(props, new Authenticator() {
@Override
protected PasswordAuthentication getPasswordAuthentication() {
return new PasswordAuthentication(fromUserName, fromUserPw);
}
});
session.setDebug(true);
// 创建邮件
Message msg = new MimeMessage(session);
msg.setSubject(pref + " : " + subject.getDes());
msg.setContent(context, "text/html;charset=UTF-8");
msg.setFrom(sendFrom);
msg.addRecipient(Message.RecipientType.TO, sendTo);
// 发送邮件
Transport.send(msg);
Serializable 接口
RMI 及网络间对象的传递与调用,需要对象的序列化,来进行传输与反序列
Java Bean 保存状态到本地
基本操作
1 | // 操作 |
- serialVersionUID
当需要序列化的类实现Serializable接口后,会自动或者让你生成一个serialVersionUID,目的: 如果一个对象在序列化存储到本地或内存中后,进行反序列时,如果serialVersionUID 不相等的,是不能反序列成功的。可用于CS中客户端的升级。
1 | private static final long serialVersionUID = 2L; |
类静态变量
对象中,类静态变量是不会进行序列的。
transient
使用transient修饰的属性,也不参与序列
反复序列
一个对象 反复序列多次,序列数据只是按特定存储方式,存储了第一次序列的指针,所以容量增加不大。
反复反序列
反复反序列,因为存储的时候是做了第一次存储的指针处理的,所以读出来的东西是同一个
关键点:在序列化的时候,如果这个对象以前序列化过,再次存储的时候,不关注这个对象现在属性是否已经变更,直接引用以前存储的对象指针进行序列存储;在反序列时,会根据存储顺序依次反序列
- 对敏感字段加密序列、反序列
在调用 writeObject 时,会查看对象是否 拥有writeObject,如果有,代表自定义序列化逻辑,这里可对加密的属性进行自定义的扩展
1 | private void writeObject(ObjectOutputStream out) {} |
StringBuffer vs StringBuilder
- 两者兼容API
- StringBuffer 线程安全
- StringBuilder 多线程不安全,但是更快
- 继承同一个超类,在超类中使用char[]数组存储,超过存储长度时,会进行复制,长度大约2倍的增长,StringBuilder 线程安全是使用synchronized 关键字实现
transient 关键字修饰代表属性不存储
Arrays.copyOf()不仅仅只是拷贝数组中的元素,在拷贝元素时,会创建一个新的数组对象。而System.arrayCopy只拷贝已经存在数组元素。Arrays.copyOf()的源码,该方法的底层还是调用了System.arrayCopyOf()方法。
Java 队列
说明
Queue:FIFO(先进先出)的数据结构,Java 1.5引入的
Queue 接口,与List,Set 同一级别,继承Collection 接口
方法详解
| 抛异常 | 返回空 | 解释 |
|---|---|---|
| add(e) | offer(e) | 向队列尾部添加 |
| remove() | poll() | 获取并删除头部 |
| element() | peek() | 获取头部 |
继承关系图
子类说明
不阻塞队列
内置的 PriorityQueue 和 ConcurrentLinkedQueue
1. PriorityQueue 类实质上维护了一个有序列表。加入到Queue中的元素根据它们的天然排序(通过其java.util.Comparable实现)或者根据传递给构造函数的java.util.Comparator 实现来定位。
2. ConcurrentLinkedQueue 是基于链接节点的、线程安全的队列。并发访问不需要同步。因为它在队列的尾部添加元素并从头部删除它们,所以只要不需要知道队列的大小。ConcurrentLinkedQueue 对公共集合的共享访问就可以工作得很好。收集关于队列大小的信息会很慢,需要遍历队列。
阻塞队列
java.util.concurrent 中加入了BlockingQueue接口和五个阻塞队列类。它实质上就是一种带有一点扭曲的FIFO数据结构。不是立即从队列中添加或者删除元素,线程执行操作阻塞,直到有空间或者元素可用。
BlockingQueue接口声明有阻塞操作put和take
- put 添加一个元素 如果队列满,则阻塞
- take 移除并返回队列头部的元素 如果队列为空,则阻塞
1. ArrayBlockingQueue :一个由数组支持的有界队列。
2. LinkedBlockingQueue :一个由链接节点支持的可选有界队列。
3. PriorityBlockingQueue :一个由优先级堆支持的无界优先级队列。
4. DelayQueue :一个由优先级堆支持的、基于时间的调度队列。
5. SynchronousQueue :一个利用 BlockingQueue 接口的简单聚集(rendezvous)机制。