简介:大数据与流式计算。Spark 的介绍,安装,使用;与Hadoop 的关系;Kafka的介绍与使用
Hadoop and Speak
简介
- Hadoop 实际上是一个分布式数据基础设施,它将巨大的数据分派到一个由普通计算机组成的集群中,同时还会索引和跟踪这些数据。
- Hadoop 应用场景,离线处理,对时效性要求不高(中间数据会落在硬盘上的)
Spark 专门用来对那些分布式存储的大数据进行处理的工具,它本身不提供分布式数据的存储,是一个快速且通用的集群计算平台
Hadoop组成
Hadoop由HDFS(分布式数据存储)+MapReduce(数据处理功能) +Hadoop Common(The common utilities that support the other Hadoop modules) +YARN(a framework for job scheduliing and cluster resource management 作业调度与集群资源管理框架)
当然这里可用使用Speak替代MapReduce,Speak本身亦可以独立存在
Spark 简介
Spark 历史
- Spark 诞生于09年 加州大学柏克利分校AMP实验室,最初基于Hadoop Mapreduce ,发现MapReduce在交互式和迭代计算上低效,引入内存存储,产生巨大区别,10年开源,11年AMP实验室在Spark上开发高级组件,像 Spark Streaming ,13年转移到Apache下,不久就变成顶级项目
Speak 背景
- Speak 官网
- Speak 是在Scala语言实现的
- Spark 是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架(现在在apache下)
- Scala 是一门多范式的编程语言,一种类似java的编程语言
Spark 组件
包含多个紧密集成的组件
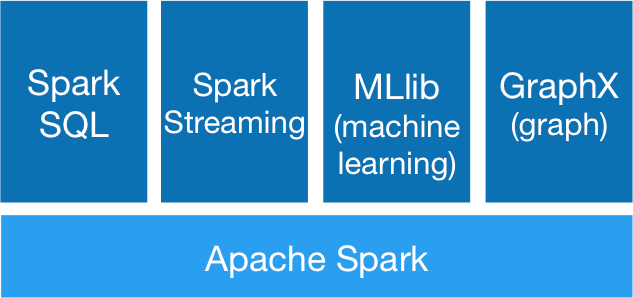
组件简介
Spark Core : 包含Spark的基本功能,包含任务调度,内存管理,容错机制等,内部定义了RDDs(弹性分布式数据集),提供了很多API来创建和操作这些RDDS,为其他组件提供服务
Spark SQL : spark 处理结构化数据的库,像hive SQL,Mysql 一样,用于企业报表统计
Spark Streaming: 是实时数据流组件,类似Storm,Spark Steaming 提供API来操作实时数据流,企业中用来从Kafka接受数据做实时统计
Mlib: 一个包含了通用机器学习功能的包,Machine learning lib。包含分类,聚聚,回归等,还有模型评估,和数据导入,都支持集群上的横向扩展
Graphx:处理图的库,并进行图的并行计算
Speak 优点
- Speed (run programs up to 100x faster than hadoop mapreduce in memory,or 10x faster on disk)
- Ease of use (Write applications quickly in java,Scala,python,R…)
- Generality –通用性 (Combine SQL, streaming, and complex analytics.)
- Runs EveryWhere
Speak应用场景
- 实时的市场活动,在线产品推荐,网络安全分析,机器日记监控
Spark 使用
Speak RDDs
Drive Program :包含程序的main() ,RDDs 的定义和操作,他管理很多节点,我们称为executors
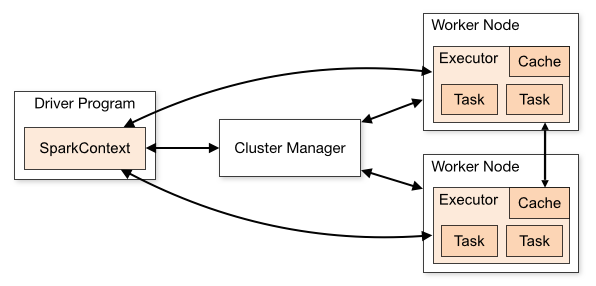
SparkContext : Driver Programs 通过SparkContext对象访问Spark,SparkContext对象代表和一个集群的连接 (在shell 中 自动创建好了的 ==> sc )
RDDs : Resilient distributed datesets (弹性分布式数据集,简称RDDs) 这些RDDs,并行的分布在整个集群中
分片: 每个分片包含一部分数据,partitions可在集群不同节点上计算,分片是Spark并行处理单元,Spark顺序,并行的处理分片
RDD 说明
RDD可以设置不同类型存储方式,只存硬盘、只存内存等。
- 只读的、分块的数据记录集合
- 可以通过读取来不同存储类型的数据进行创建、或者通过RDD操作生成(map、filter操作等)
- 使用者只能控制RDD的缓存或者分区方式
- RDD的数据可以有多种类型存储方式(可(序列化)存在内存或硬盘中)
RDD 存储类型
RDD可以设置不同类型存储方式,只存硬盘、只存内存等。
RDD操作

Transformation:根据已有RDD创建新的RDD数据集build
从之前的RDD构建一个新的RDD,像 map(),filter(),flatMap()
集合运算:去重 distanct(),并集 union(),交集 intersection(),去交集
- Action:在RDD数据集运行计算后,返回一个值或者将结果写入外部存储
在Rdd上计算出来一个结果
把结果返回给driver program 或保存在文件系统中,如count(),save()
reduce() 接收一个函数,作用在Rdd两个类型相同的元素上,返回新元素,可实现元素的累加,计数
collect()
take(n) 返回结果是无序的
top() 排序的最大
foreach() 计算Rdd中的每个元素,但不返回到本地
RDD如何创建
1.首先创建JavaSparkContext对象实例sc
JavaSparkContext sc = new JavaSparkContext("local","SparkTest");
接受2个参数:
第一个参数表示运行方式(local、yarn-client、yarn-standalone等)
第二个参数表示应用名字
2.转换RDD
直接从集合转化 sc.parallelize(List(1,2,3,4,5,6,7,8,9,10))
从HDFS文件转化 sc.textFile("hdfs://")
从本地文件转化 sc.textFile("file:/")
RDDs的特性
血统关系图
- Spark维护这RDDs之间的依赖关系和创建关系,叫血统关系图
- Spark使用血统关系图来计算每个RDD的需求和恢复丢失数据
延迟计算
- Spark对RDDs的计算是他们第一次使用action操作的时候
- 这种方式可以减少数据的传输
- Spark内部记录metadata表明transformations操作已经被响应
- 加载数据也是延迟计算,数据只有在必要的时候才会被加载
RDD.perist()
- 默认每次RDDs上面进行action操作时,Spark都会重现计算RDDs,如果想重复利用一个RDD,可以使用RDD.persist(),相应的 unpersist()则是从缓存中移除(方法接受配置参数)
RDD操作Java Api
- map() : map操作对数据集每行数据执行函数里面操作
- flatMap() : flatMap相比于map操作,它对每行数据操作后会生成多行数据,而map操作只会生成一行。
- filter() : filter对每行数据执行过滤操作,返回true则保留,返回false则过滤该行数据
- union() : union操作对两个RDD数据进行合并。与SQL中的union一样
- groupByKey() : groupByKey对pair中的key进行group by操作
- reduceByKey() : reduceByKey对pair中的key先进行group by操作,然后根据函数对聚合数据后的数据操作
- mapValues() : mapValues操作对pair中的value部分执行函数里面的操作
- join() : join与sql中join含义一致,将两个RDD中key一致的进行join连接操作
- cogroup() : cogroup对两个RDD数据集按key进行group by,并对每个RDD的value进行单独group by
###RDD数据如何输出
使用RDD的Transformation对数据操作后,需要再使用Action操作才能将结果数据输出
可以分别使用count、collect、save等操作来输出或统计RDD结果
调度机制
TODO
spark 安装
- spark 如何在本地代码中进行测试,可以直接创建一个local的运行环境,不需要单独的安装,相当于storm的本地测试模式
- spark 解压后,/bin 下面有很多工具 :
- 可支持shell来处理,目前支持 py 和 scala (不需要事先启动spark服务,相当于本地模式)
- run-example 各种测试例子
- spark-sql
- spark-submit 提交工具
- spark /sbin 关于服务的启动相关脚本
安装方式
- 内嵌测试启动: 在shell中直接使用,或者在代码中自定义local 来new 都是内嵌启动,
- 单机独立启动: 启动一个master 和N个 slaver 这是单机独立启动在一台服务器上
- 多机独立启动: 一台部署master,其他服务器上部署部署 slaver ,形成一个集群
- 基于mesos集群启动: TODO
- 基于yarn 集群启动: TODO
启动之后,会有一个监控页面: http://maserIp:8080 会监控集群状态,如果有任务跑时,会一个4040 job网页监控job
Kafka
简介
kafka 是一个高吞吐量的分布式发布订阅消息系统,它最初由LinkedIn公司开发,之后成为Apache项目的一部分.
特性
- 通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于及时TB级的消息存储也能保证长时间的稳定性
- 高吞吐量,即使是非常普通的硬件Kafka也可以支撑每秒数百万的消息
- 支持通过kafka服务器和消费机集群来分区消息
- 支持Hadoop并行加载数据
相关术语
- Broker : kafka集群包含一个或多个服务器,这种服务器被称为broler
- Topic : 每条发布到Kafka集群的消息都有一个类别,这种类别称为Topic,(物理上不同的Topic的消息分开存储,逻辑上一个Topic消息虽然保存于一个或多个broker上,但用户只需指定消息的topic即可生产或消费数据,而不必关系存储何处)
- Partition : 物理上的概率,每个topic包含一个或多个Partition
- Producer : 负责发布消息到Kafka broker
- Consumer : 消息消费者,向Kafka broler 读取消息的客户端
- Consumer Group : 每一个Consumer属于一个特定的Consumer Group ,可为每个Consumer指定group ,如果不指定,则属于默认的group
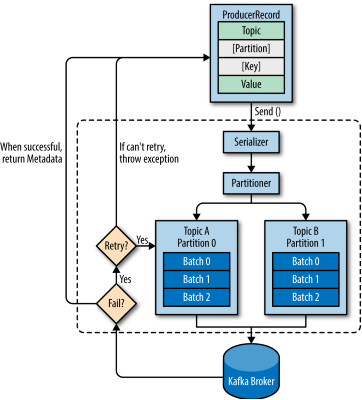
Kafka 存储
- kafka的存储布局非常简单,topic的每个partition 对应一个逻辑日志,物理上,一个日志为相同大小的一组分段文件,每次生成这发布消息到一个分区,代理就将消息追加到最后一个段文件中,当发布的消息数量达到设定值或者经过一段时间后,段文件真正写入磁盘中,写入完成后,消息公开给消费者。
- 与传统的消息系统不同,Kafka系统中存储的消息没有明确的消息ID
- 消息通过日志中的逻辑偏移量来公开,这样就避免了维护配套密集寻址,用于映射消息ID到实际消息地址的随机存储索引结构的开销,消息ID是递增的,但是不连续,要计算下一个消息的ID,可以在其逻辑偏移量的技术上加上当前消息的长度
- 消费者始终从特定分区顺序地获取消息,如果消费者知道特定消息的偏移量,也就说明消费者已经消费了之前的所有消息。消费者向代理发出异步拉请求,准备字节缓冲区用于消费。每个异步拉请求都包含要消费的消息偏移量。Kafka利用sendfile API高效地从代理的日志段文件中分发字节给消费者

Kafka性能要好很多的主要原因包括:
- Kafka不等待代理的确认,以代理能处理的最快速度发送消息。
- Kafka有更高效的存储格式。平均而言,Kafka每条消息有9字节的开销,而ActiveMQ有144字节。其原因是JMS所需的沉重消息头,以及维护各种索引结构的开销。LinkedIn注意到ActiveMQ一个最忙的线程大部分时间都在存取B-Tree以维护消息元数据和状态。
Kafka 集群安装
- kafka 依赖于zookeeper(集群或者单独),所以需要一个zk,他本身提供一个单独的zk,当然也可以自己创建一集群
zookeeper 集群安装完成后, 修改kafka文件夹下config/server.properties
broker.id=0 --每台服务器的broker.id都不能相同 listeners=PLAINTEXT://192.168.1.5:9092 --kafka监听端口,外部可以访问 zookeeper.connect=192.168.1.3:2181,192.168.1.4:2181,192.168.1.5:2181 -- ZK的集群地址- 每台启动 bin/kafka-server-start.sh config/server.properties
单机版的kafka只要单独启动就OK了(内嵌的zk+kafka启动)
Kafka 使用
常见的shell 命令
创建topic
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor X --partitions 1 --topic test 注: x 设置为集群数查看当前集群中所有的topic
bin/kafka-topics.sh --list --zookeeper localhost:2181sendmsg(生产者生成)
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic testconsumer(消费者消费)
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginningdescribe topics
bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-replicated-topic